最长回文子串算法——Manacher算法
最长回文子串算法——Manacher算法
Manacher算法是一个用来查找一个字符串中的最长回文子串(不是最长回文序列)的线性算法。其优点就是把时间复杂度从暴力算法的O(n2)优化到O(n)。
Manacher 算法,又被中国程序员戏称为“马拉车”算法
暴力匹配算法
暴力匹配算法的原理
暴力匹配算法的原理很简单,如下:
- 依次向尾部进行遍历,访问一个字符;
- 以此字符为中心点向两边扩展,记录该点的最长回文长度;
- 取各个字符的回文子串长度的max。
暴力匹配算法存在的问题
偶数回文串需要额外修改
在奇数字符串中,例如
aba,对应的回文长度是131。而例如abba,以使用中心扩展的比较原则下计算出来的回文长度是1111,我们对奇数回文串求出了正确答案,但是在偶数回文串上并没有得到我们想要的结果,需要针对偶数情况进行额外修改。时间复杂度O(n2)
外层需要遍历每一个字符,而每到一个新字符就需要向两边扩展比对,所以时间复杂度达到了O(n * n)。
Manacher算法本质上也是基于暴力匹配的方法,只不过做了一点简单的预处理,且在扩展时提供了加速
Manacher算法的预处理
Manacher算法对偶数字符串做了预处理,这个预处理可以巧妙的让所有(包括奇和偶)字符串都变为奇数回文串。操作实现也很简单,就是将原字符串的首部和尾部以及每两个字符间插入一个特殊字符(假设为#号),这个字符不会影响最终的结果,这一步预处理操作后的效果就是原字符串的长度从n改变成了2n + 1。比如我们的原字符串是
abba,假设预处理后的字符串是
#a#b#b#a#,我们在任意一个点,比如字符
#,向两端匹配只会出现原始字符匹配原始字符,#匹配
#
的情况,不会出现原字符串字符与特殊字符匹配的情况,这样就能保证我们不会改变原字符串的匹配规则。该预处理得到进行下一步扩展的字符串,并且从预处理后的字符串得到的最长回文字符串的长度除以2就是原字符串的最长回文子串长度,也就是我们想要得到的结果。
Manacher算法核心
概念
ManacherString:经过Manacher预处理的字符串,以下的概念都是基于ManasherString产生的。回文半径:经过处理后的字符串的长度一定是奇数,回文半径就是以回文中心字符的回文子串长度的一半。
回文直径:回文半径 * 2 − 1。
最右回文边界R:遍历字符串时,每个字符的最长回文子串都会有个右边界,而R则是所有已知右边界中最右的位置。R值保持单增。
回文中心C:取得当前R的上一次更新时候的回文中心。
半径数组P[]:该数组记录原字符每一个字符对应的最长回文半径。
算法流程
步骤1:将原字符串转换为ManacherString,定义为S
步骤2:R和C的初始值为−1,创建半径数组P[]
- 存在与概念相差的小偏差,R实际是最右边界位置的右一位。
步骤3:开始从下标i = 0到len(S) − 1,去遍历字符串S
后续存在多个分支,总览如下:
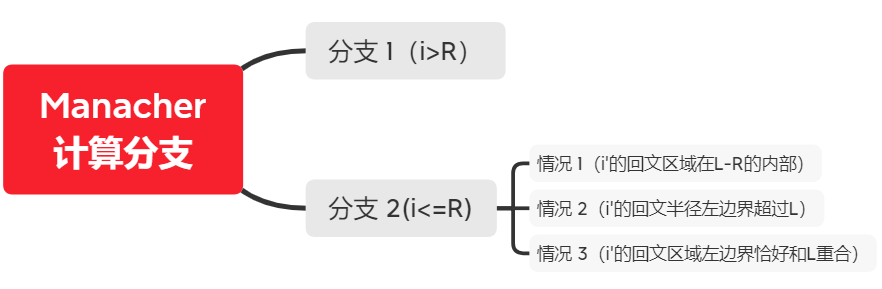
分支1:当 i > R
时,暴力匹配当前i位置字符的最长回文长度,并判断更新R和C。例如aabcd:
i = 0,R = −1 时,初次更新R = 1(i = 0字符a的最长回文右边界下标0的右一位),C = 0
分支2:i ≤ R 时,也就是说当前i下标的字符已经在某个字符的回文半径覆盖中,该分支存在三种情况,解释三种情况前,需要先理解以下模型:
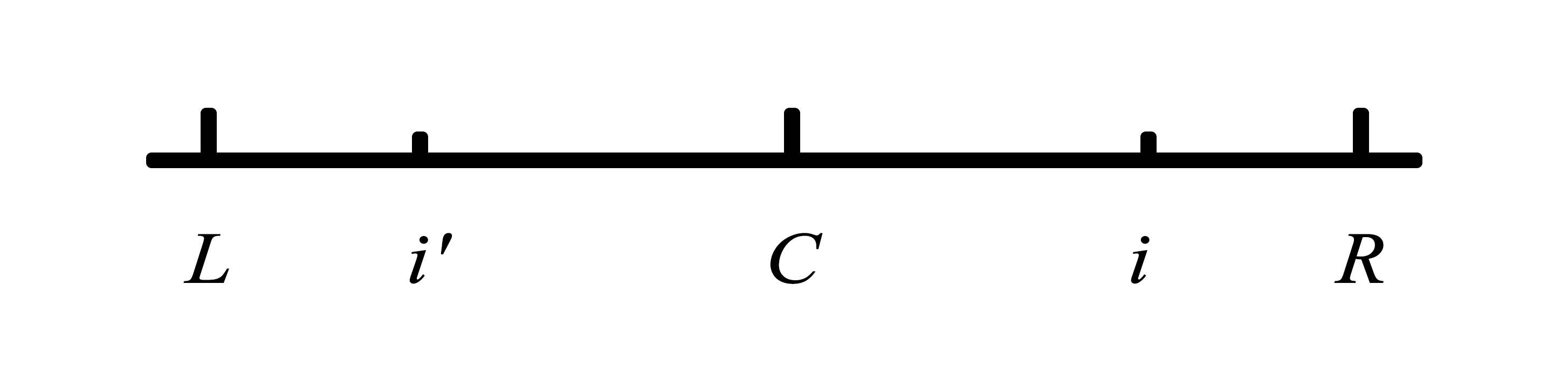
L是当前R关于C的对称点,i′是i关于C的对称点,因此i′ = 2 * C − i,并且因为从左至右遍历i,所以i′的回文区域是前面已知的(信息保存在半径数组P[i′]中)。我们可以依赖该信息判断是否进行加速。
情况1:i′的回文区域在$\overline{LR}$的内部,因为整个$\overline{LR}$就是一个回文串,我们可以直接得出i的回文直径与i′相同。

情况2:i′的回文半径左边界超过L,这种情况,仅能保证i的回文半径是i到R。
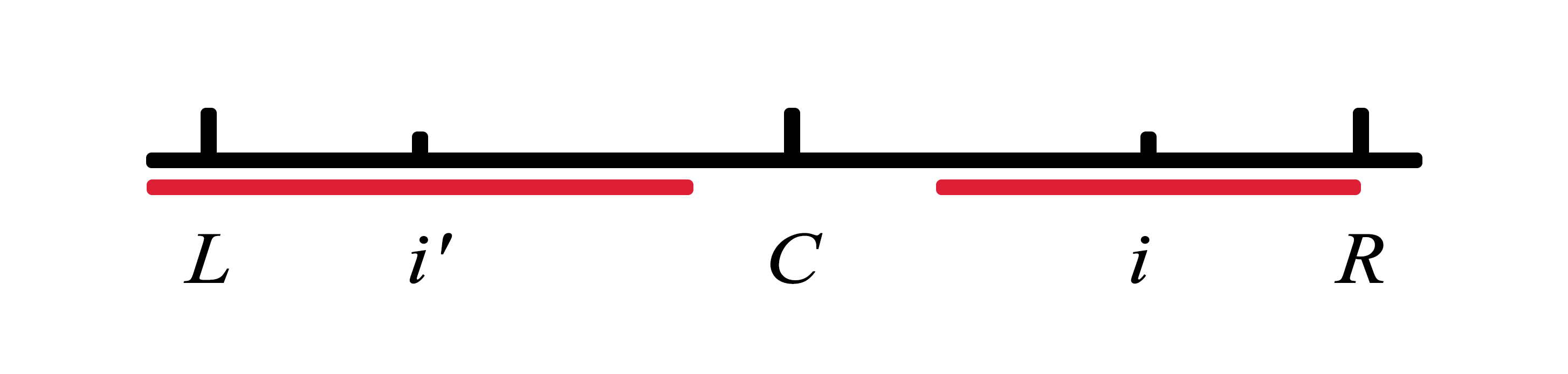
情况3:i′的回文区域左边界恰好和L重合,此时i的回文半径至少是i到R,并且回文区域从R继续向外部匹配。
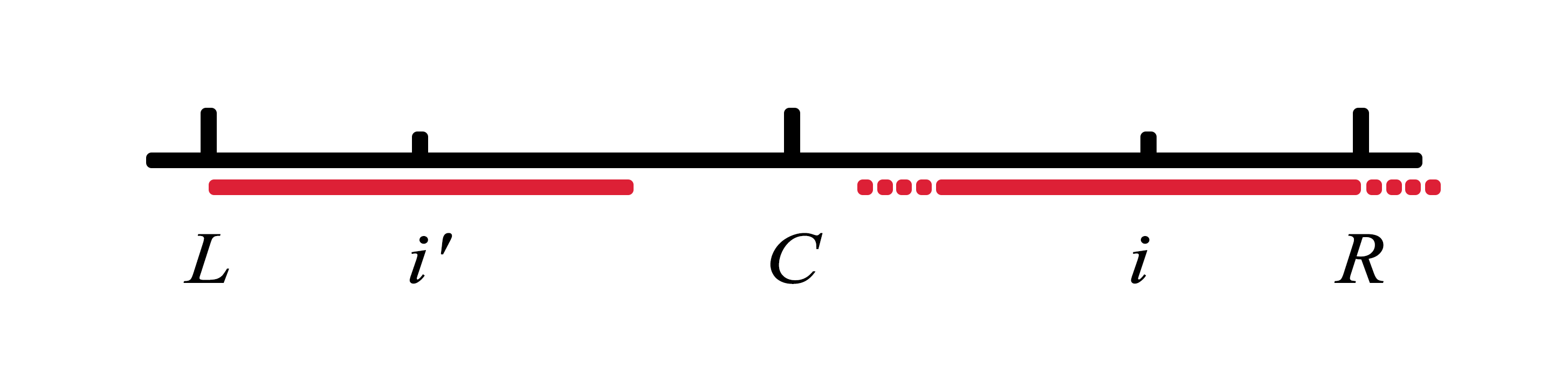
时间复杂度
Manacher算法时间复杂度为O(n)。我们可以想象下,这就是一个 i在追逐R的游戏,无非两种情况:
- R不动,同时i向右追一步。(花O(1)时间计算P[i])
- R继续往右走几步,同时i追上一步。(所谓更新R,更新C)
当R到达最右边界以后,就剩下i一步一步追上来。
因此,每个字符最多被访问两次,一次被R经过,一次被追赶的i经过。所以时间复杂度是O(2 * (2n + 1)) = O(n)。
代码
代码引用自我的github仓库地址:longest-palindromic-substring.go
有关题目可参考Leetcode题目: Longest Palindromic Substring