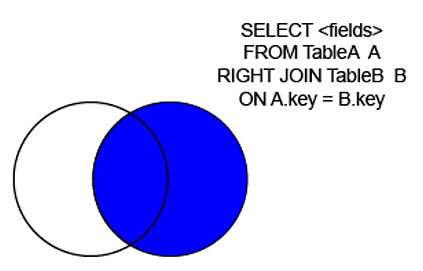
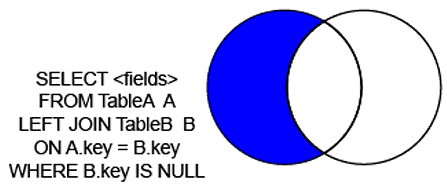
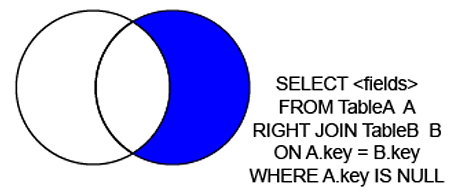
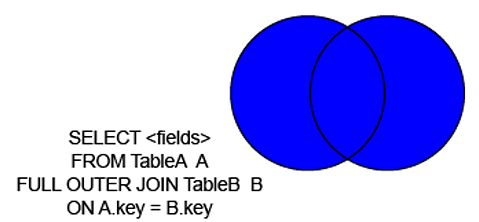
成都电信光猫盒子(天邑808AE)破解超级密码记录
成都电信光猫盒子(天邑808AE)破解超级密码记录
最近换了工作地点,新租房的房东默认配置了电信宽带,附带上宽带盒子,这个盒子算是一个多功能盒子,包括以下功能:
- 光猫
- 电视盒子(IPTV安卓4.4系统 + 带红外遥控 + 视频/音频HDMI接口 + 音频SPDIF接口)
- 路由(一个千兆网口 + 一个百兆网口)
- 2.4G WIFI(带WPS)
- 电话(RJ11接口)
还带两个USB2.0接口和SD卡接口,但侧边的USB和SD卡接口都是给IPTV安卓系统使用,只有后面的USB接口可以拿来做存储使用,该口也用作后面的破解密码使用。
进入正题,接下来介绍具体的过程:
1. 获取管理界面
一般运营商所附赠的盒子都会在背面标注配置地址,常为192.168.1.1,也会标注上配置账号和密码(下称useradmin账户),访问网页结果如下,目前该设备的账号名为useradmin。
破解超级密码记录/屏幕截图 2021-07-21 222537.png)
使用给定的useradmin账户登录,查看设备详情,如下图。如果是相同或者相近的产品型号,可以根据我的思路进行破解。
破解超级密码记录/屏幕截图 2021-07-21 222846.png)
需要注意,该界面,基本只能用于修改修改wifi配置信息,该配置地址192.168.1.1也是一个非运维地址,真正运维地址是192.168.1.1:8080,该网页访问情况如下:
破解超级密码记录/屏幕截图 2021-07-21 222708.png)
目前,可以使用useradmin账户登录该管理界面,但也存在权限问题。虽然相较于之前的页面多了一些配置内容,但基本都是些无关痛痒的操作,并不能实现对宽带拨号、桥接、IPV6等的修改。要实现完全功能的修改,需要使用真正给运维人员的账户(下称telecomadmin账户),接下来,我们将使用useradmin账户+运维地址192.168.1.1:8080来获取telecomadmin账户。
2. 利用小trick拿到备份文件
在广大网友的智慧下,使用useradmin账户登录运维地址,然后打开开发者界面(快捷键F12),切换到网络面板。然后网页访问:管理→设备管理,在网络请求中找到:MD_Device_user.html,见下图:
破解超级密码记录/屏幕截图%202021-07-21%20223029.png)
该HTML源码中有个函数enableClick(),作用是实现将盒子配置内容备份到USB存储设备中。但在网页中并没有提供触发这个函数的操作(比如点击某个按钮),需要我们手动触发。
1 | //USB 快速恢复 启用/禁用 |
分析该函数,发现只需要拼接一个字串,就可以访问该功能。其中enabled代表是否启用USB快速恢复功能,当然此处需要启用。最后拼接如下:
1 | loc = usbbackup.cmd?action=backupeble&enabled=1&sessionKey=1795138985 |
这里的sessionKey来源在源码的上方
1 | var obj1Items = '1|7|0'; |
给出了 sessionKey 的值,复制过来,拼接成一个完整的字串。
懂URL编码的同学可以发现,该字串就是http请求url的一部分,其中的 enabled 和 sessionKey 都是GET请求的 params
然后补上前面的地址部分,形成一个完整的访问网址:
192.168.1.1:8080/usbbackup.cmd?action=backupeble&enabled=1&sessionKey=1795138985
一定要创建一个新页面,然后打开开发者工具,去访问该网页。如果顺利,会得到一个这样的网页:
破解超级密码记录/屏幕截图 2021-07-21 223641.png)
但是由于 sessionKey 有访问时间、次数限制,如果短时间没有进行操作或者重复操作,会访问失败,得到如下结果。
破解超级密码记录/屏幕截图 2021-07-21 223417.png)
如遇到这样的情况,请重新访问:管理→设备管理,拿到新的 sessionKey 来访问该网页。下图是是正常的访问页面。
破解超级密码记录/屏幕截图%202021-07-21%20223641.png)
在某些设备中,除上图中的三个按钮(恢复出厂设置、重启、保存设置)外,还有有一个备份配置的按钮,如下:
破解超级密码记录/屏幕截图 2021-07-21 223814.png)
- 注:该图来源于网络,我的设备没有备份配置按钮
如果你有备份配置按钮,可以提前插入U盘(最好格式化为Fat32格式),然后点击备份配置,得到一个
cfg 类型文件,跳过之后的步骤到第3步。
如果你遇到我这样没有备份配置按钮的情况,那么😒,还需要绕一圈。我们继续使用开发者工具,查看该界面代码:
1 | ... |
发现product_type还做了限制,必须product_type=4的设备才能有该功能。不过我们可以继续梳理逻辑,如果存在该功能,当点击备份配置按钮的时候,会访问到btnApply()函数,继续找到该函数:
1 | function btnApply() { |
又是一个拼接函数,继续按照逻辑拼接,得到如下的结果:
1 | loc = usbbackup.cmd?action=backup&subarea=usb1_1&sessionKey=1222473631 |
其中的 subarea 值和 sessionKey 的值可以在该页面的上方找到:
1 | var obj1Items = '1|7|0'; |
- 注:若usblist 值为空串, 请插上U盘重试,建议U盘格式化为Fat32格式。
保证设备后面插上U盘,并形成一个完整的链接:
192.168.1.1:8080/usbbackup.cmd?action=backup&subarea=usb1_1&sessionKey=781652989
- 注:subarea 字段值为 sublist
以
|隔断的第一个字串。
访问该链接,如果顺利,不会有访问异常,而且在U盘目录下新生成有如下cfg类型文件:
破解超级密码记录/屏幕截图%202021-07-21%20224041.png)
如果没有该文件,请尝试重试以上步骤🙄,尤其是 sessionKey 的获取有效。
3. 使用routerpassview 获取超级密码
如果拿到cfg文件,在网络上搜索下载routerpassview软件,并用该软件打开U盘内的cfg文件。如果软件被杀毒软件拦截,请酌情放行。
破解超级密码记录/屏幕截图 2021-07-21 224231.png)
在软件中查找telecom关键词(快捷键Ctrl +
F),如果能找到如图的内容,恭喜你破解telecomadmin账户成功👍。账号名为telecomadmin,账户密码为图中Password中间标识的字段,该密码跟随设备,相同设备间一般不一样,甚至同一设备恢复出厂设置后都有可能会修改。
最后,使用telcomadmin账号登录运维地址
破解超级密码记录/屏幕截图 2021-07-21 224311.png)
附上 useradmin 账号和 telcomadmin 账号登录运维地址的截图,可以看到多出来的配置功能。
telecomadmin账号登录运维截图
破解超级密码记录/屏幕截图 2021-07-21 224419.png)
useradmin账号登录运维截图
破解超级密码记录/屏幕截图%202021-07-21%20224501.png)
.png)