RTL8367S自制网管交换机
RTL8367S自制网管交换机

RTL8367S 芯片官网介绍
RTL8367S-CG
二层管理 5+2 端口 10/100/1000M 交换机控制器
概述
RTL8367S-CG 是一款 LQFP-128 封装的高性能 5+2 端口 10/100/1000M 以太网交换机,具有低功耗集成 5 端口 Giga-PHY,支持 1000Base-T、100Base-TX 和 10Base-T传输标准。
对于特定应用,RTL8367S 支持一个额外的接口,可配置为 RGMII/MII 接口。 RTL8367S 还支持一个可配置为 SGMII/HSGMII 接口的 Ser-Des 接口。 RTL8367S集成了高速交换机系统的所有功能;包括用于数据包缓冲的 SRAM、无阻塞交换结构以及单个 CMOS 器件中的内部寄存器管理。
特点
单芯片 5+2 端口 10/100/1000M 无阻塞交换架构
嵌入式 5 端口 10/100/1000Base-T PHY
每个端口支持全双工 10/100/1000M 连接(半双工仅在 10/100M 模式下支持)
额外接口(扩展 GMAC1)支持
SGMII (1.25GHz) 接口
HSGMII (3.125GHz) 接口
额外接口(扩展GMAC2)支持
媒体独立接口 (MII)
简化的 10/100/1000M 媒体独立接口 (RGMII)
通过 IEEE 802.3x 流量控制和背压进行全双工和半双工操作
应用
5 端口 1000Base-T 路由器,带 SGMII/HSGMII 和/或 MII/RGMII
芯片官网介绍:https://www.realtek.com/Product/Index?id=3699
RTL8367S-CG_Datasheet.pdf1
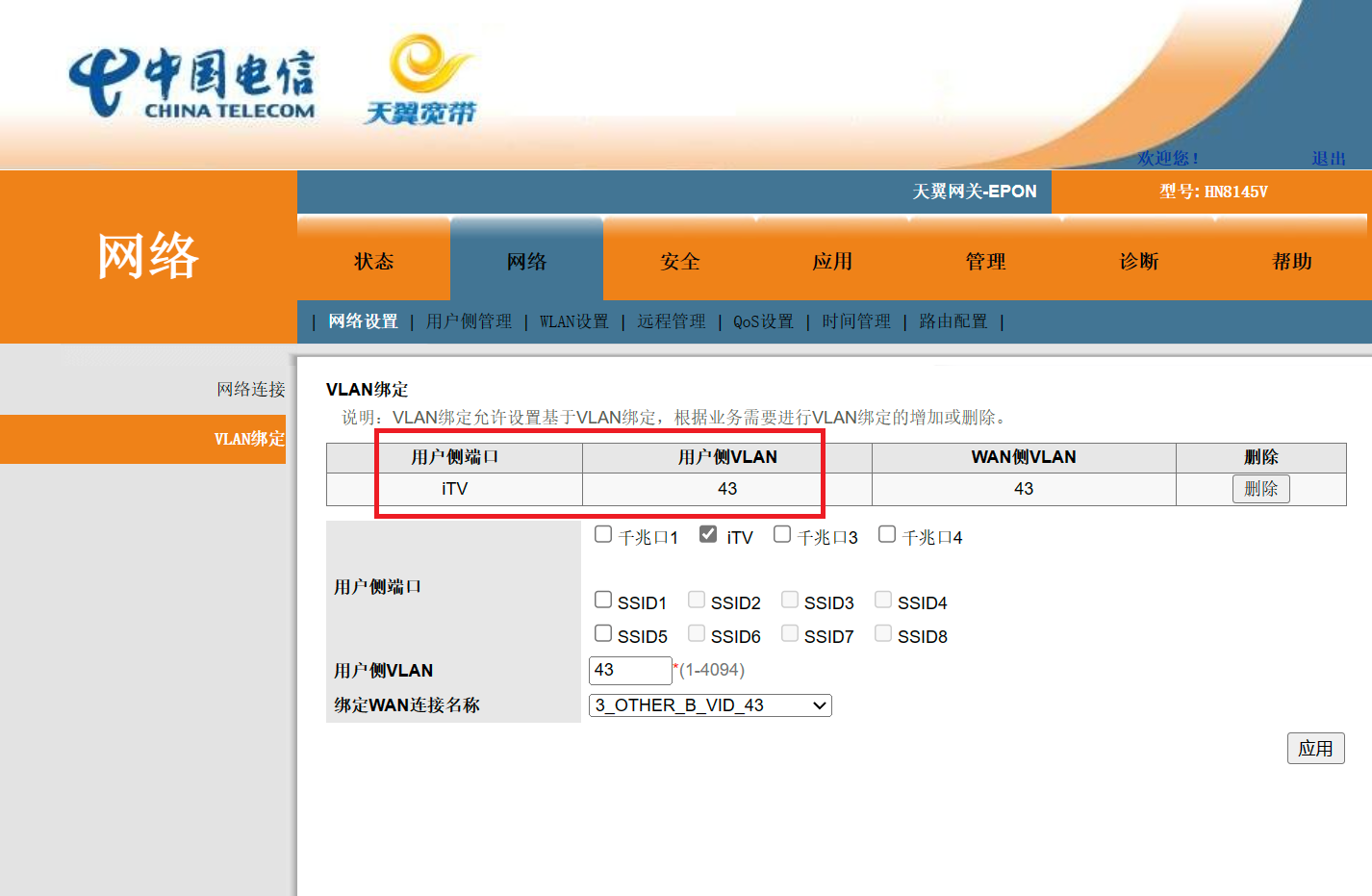
原理图
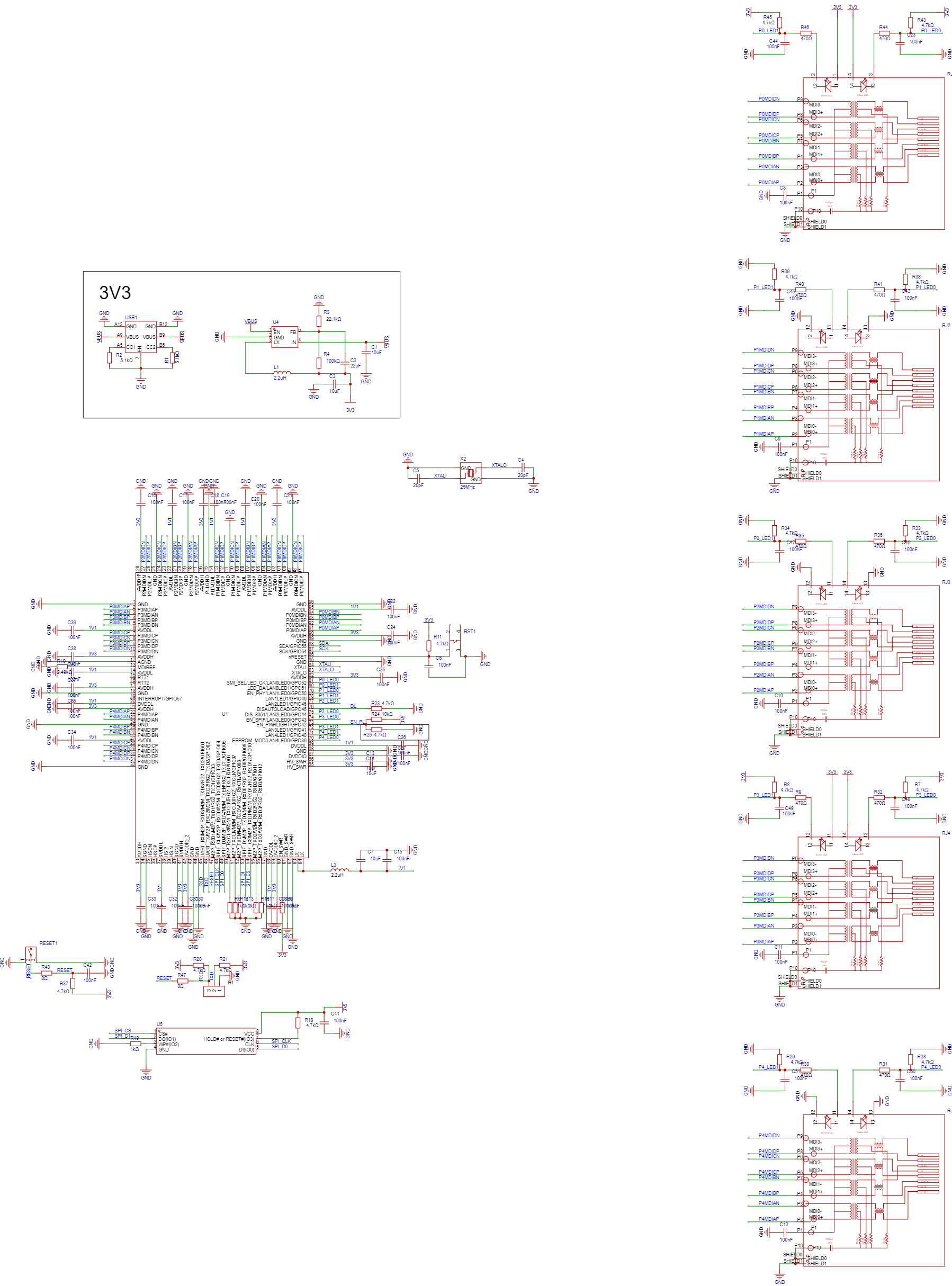
外围电路
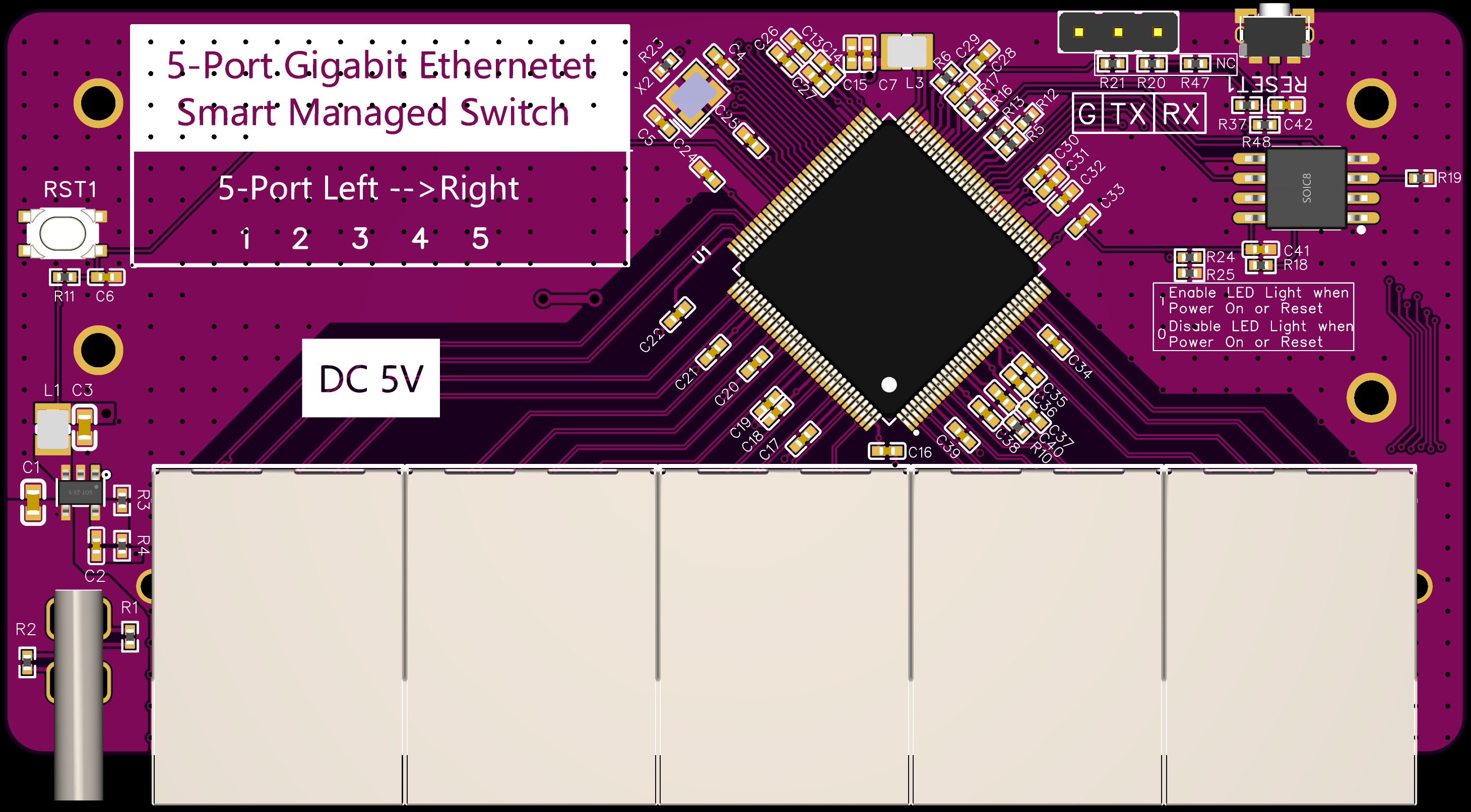
- 使用 USB-C 输出5V电源
- 使用 SY8088IAAC 实现 5V 降压 3.3V,使用RTL8367S自带电压转换输出1.1V
- 使用 W25Q32JVSSIQ 4MB spi norflash 存储固件
- 使用 5个 HR911130A 自带变压器和 LED 的单端口RJ45连接器
- 转出 TX/RX 串口
- 带 3.3V 供电拉低按钮 + 芯片重置按钮
- 25M 晶振时钟
3D效果图
固件
借用网件GE105Ev2的固件 
https://www.netgear.com/cn/business/wired/switches/plus/gs105ev2/
网件固件.bin,大小2M。
使用烧录器(例如CH341)烧写到 spi norflash中。
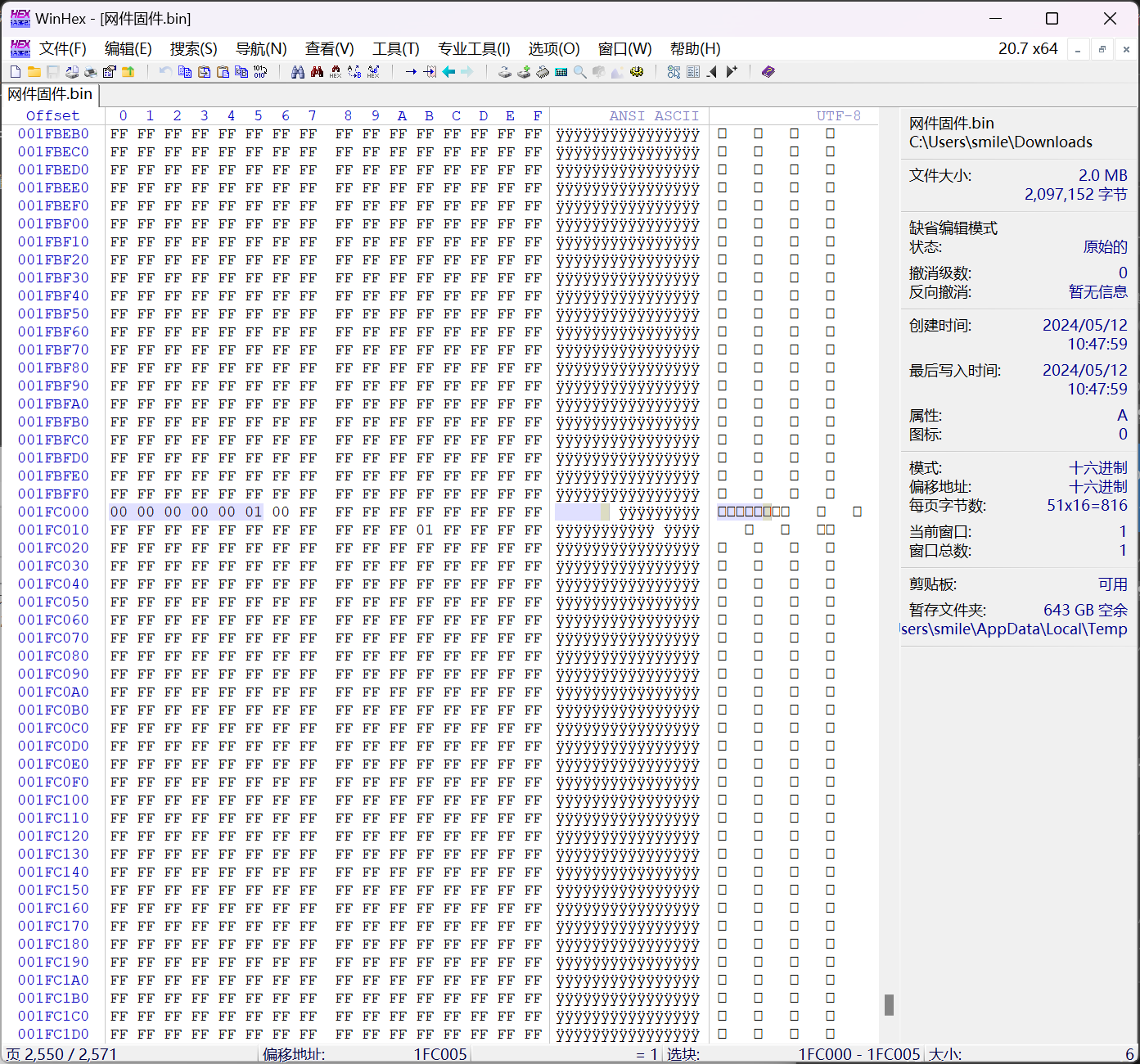
修改mac地址
固件MAC地址固定为00:00:00:00:00:01,编辑固件中偏移地址
0x1FC000指定MAC地址,可以随机生成MAC
 数组长度的声明表达式中,如果表达式是一个常量表达式,它的值应该大于零。
数组长度的声明表达式中,如果表达式是一个常量表达式,它的值应该大于零。