描述命令行参数
描述命令行参数
1 | 命令 <必选参数|必选参数> [--option <参数1|参数2|参数3>] |
- <> 尖括号:必选参数;
- [] 方括号:可选参数,按需使用;
- | 竖线:用于分隔多个互斥参数,使用时只能选择一个;
- - 连字符: 表示参数名,-- 表示全称,- 表示简写;
1 | 命令 <必选参数|必选参数> [--option <参数1|参数2|参数3>] |
一般服务器或交换机上的风扇接口都会走以下几种信号:
| 线定义 | 线常用颜色 | 功能描述 |
|---|---|---|
| POWER/VCC | 红色 | 供电,一般为12V |
| GND | 黑色 | GND接地 |
| PWM | 蓝色 | 调速信号,方波占空比 |
| TACH/FG | 黄色或白色 | 测速信号,可用作闭环控制 |
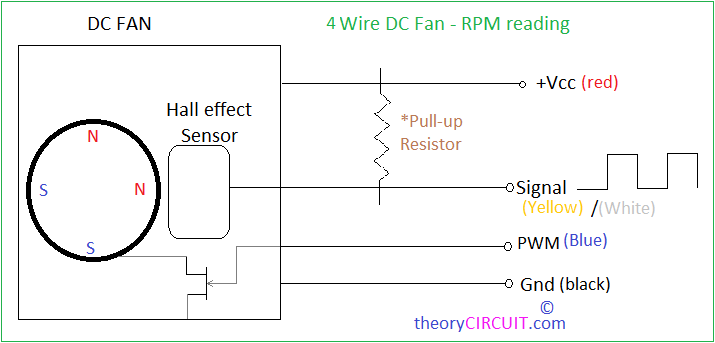
TACH(Tachometer)信号,转速表的意思,一些说明书里也被称为FG(Frequency
Generator)信号。注意TACH是开集电极输出,需要上拉电阻。
TACH信号输出的是一个频率可变的方波信号。其原理是,在风扇转子旁边布置了一个霍尔传感器,当电机转动的时候,电机的转子的磁体经过霍尔传感器时,输出一个高电平,经过信号处理后输出一个方波。因为转子转一圈一般会输出2个方波信号,因此方波的2个周期的时间就是电机转子转动一圈的时长。因此,电机转速
rpm = Freq方波 * 60/2
,单位为 rad/min
。
在实际检测电路中,定义常量 Npuls 表示风扇每转一圈产生脉冲个数,一般为2;定义一个测量时间窗 Tmea (例如500ms);设置一个计数器 M(例如8bit),用于统计时间窗内收到的脉冲数; 那么风扇转速为: rpm = M * 60/(Tmea * Npuls) ,单位为 rad/min 。因为计数器 M 存在最大值,如果风扇的满转速过高,需要配置减小测量的时间窗以匹配。
基于项目 smilelc3/MyLittleTool
和 smilelc3/sudoku-solver,并使用
wasm
技术实现 JavaScript 调用 C/C++ 和
Go。
某些题目,由于要计算的答案非常大(超出64位整数的范围),会要求把答案对 109 + 7取模。如果在计算中途没有处理得当的话,会出现WA(错误)或则TLE(超时)。
例如计算多项乘积时,如果没有中途及时取模,乘法结果会溢出(例如C/C++),从而得到非预期的答案 。对于 Python 来说,虽然没有溢出,但是大整数(big integer)之间的运算不是 O(1),可能会导致LTE。
一般涉及到取模($\bmod$)的题目,会用到如下两个恒等式 $$ \begin{align} (a+b) \bmod m &= ((a \bmod m) + (b \bmod m)) \bmod m \\ (a \cdot b) \bmod m &= ((a \bmod m) \cdot (b \bmod m)) \bmod m \\ \end{align} $$
证明:根据带余除法,∀a ∈ 𝕫,都可以表示为a = qm + r (m ≠ 0),其中整数q为a除以m的商(quotient),整数r为a除以m的余数(remainder),即r = a mod m。
设a = q1m + r1,b = q2m + r2。 第一个恒等式: $$ \begin{align} (a+b) \bmod m &= (q_1 m + r_1 +q_2 m + r_2) \bmod m \\ &=((q_1 + q_2)m + r_1 + r_2) \bmod m \\ &=(r_1 + r_2) \bmod m \end{align} $$ 又因为r1 = a mod m,r2 = b mod m有: (a + b) mod m = ((a mod m) + (b mod m)) mod m
第二个恒等式: $$ \begin{align} (a\cdot b) \bmod m &= ((q_1 m + r_1)(q_2 m + r_2)) \bmod m \\ &= (q_1 q_2 m^2 + (q_1 r_2 + q_2 r_1)m + r_1 r_2) \bmod m \\ &=(r_1 r_2) \bmod m \end{align} $$
同样有: (a ⋅ b) mod m = ((a mod m) ⋅ (a mod m)) mod m
根据这两个恒等式,我们可以在计算过程中(例如循环中),对加法和乘法的结果取模,而不是在计算最终结果后再取模。
注意:如果涉及到幂运算,不能随意取模。如果指数为整数,可以用快速幂。
如果计算过程中有减法,可能会产生负数,处理不当也会导致 WA。如何正确处理这种情况呢?
首先引入同余(congruence modulo) 的概念。 两个整数a,b,若它们除以正整数m所得的余数相等,则称a,b对于模m同余,记作: a ≡ b (mod m)
例如42 ≡ 12 (mod 10),因为42和12都可以被10整除,余数都是2。
对于负数,我们可以将其转化为对应的非负数再取模。例如,−17 mod 10可以转化为((−17 mod 10) + 10) mod 10 = (−7 + 10) mod 10,结果是3。 也就是说,如果我们发现 (x mod m) < 0,可以加上一个m,得到非负数。
为避免判断x mod m < 0,可以写成 (x mod m + m) mod m
这样无论x是否为负数,运算结果都会落在区间[0, m − 1]中。
如果要计算$\frac{24}{8} \bmod 5$,如果像加法或乘法处理,写成$\frac{24 \bmod 5}{8 \bmod 5} \bmod 5 = \frac{4}{3}$,明显不是正确答案3。先有结论:
如果p是一个质数,a是b的倍数且b和p互质,那么有 $$ \frac{a}{b} \bmod p = (a \cdot b^{p-2}) \bmod p $$
如果实际题目中推导出了包含除法的求余式,可以用上式转换成乘法,并用快速幂计算bp − 2 mod p。
证明:
其中 $$ \mathrm{C}_p^i = \frac{p!}{i!(p-i)!} $$ 证明:当p是质数且1 ≤ i ≤ p − 1时,$\frac{p!}{i!(p-i)!}$分母一定不含p,由于分子中包含p且Cpi为整数,所以Cpi一定能被p整除,即Cpi ≡ 0 (mod p)。
当p为质数,且x, y ∈ 𝕫时,除去k = 0和k = p两项,根据引理1,其余项与0关于p同余。即 $$ \sum_{k=1}^{p-1}{\mathrm{C}_p^k x^{p-k} y^k} \equiv 0 \pmod p $$ 拆分 $$ \begin{align} (x+y)^p &= \mathrm{C}_p^0 x^p y^0 + \sum_{k=1}^{p-1}{\mathrm{C}_p^k x^{n-k} y^k} + \mathrm{C}_p^p x^0 y^p \\ &=x^p + y^p + \sum_{k=1}^{p-1}{\mathrm{C}_p^k x^{n-k} y^k} \end{align} $$
于是当p为质数,且x, y ∈ 𝕫时,有: (x + y)p ≡ xp + yp (mod p)
根据费马小定律,对任意整数a和任意质数p,有: ap ≡ a (mod p) 证明:当a = 0时,0p ≡ 0 (mod p)成立; 已知引理2,通过归纳法,我们可以得到: (x1 + ... + xn)p ≡ x1p + ... + xnp (mod p)
如果将a展开为a个1相加,a = 1 + ... + 1,代入上式有: ap ≡ (1 + ... + 1)p ≡ 1p + ... + 1p ≡ a (mod p)
根据数学归纳法,原命题对于 a ≥ 0 成立。对于a < 0的情况同理,证明完毕。
如果a不是p的倍数,费马小定理也可以写成更加常用的一种形式: ap − 1 ≡ 1 (mod p) 如果a是p的倍数,显然有:ap − 1 ≡ 0 (mod p)。
在a不是p的倍数的前提下,两边同时乘以$\frac{b}{a}$,有 $$ b \cdot a^{p-2} \equiv \frac{b}{a} \pmod p $$
即 $$ \frac{b}{a} \bmod p = (b \cdot a^{p-2}) \bmod p $$
1 | // 如果取模到 [0, MOD-1] 中,无论正负 |