SIFT算法深入理解
SIFT算法深入理解
SIFT(Scale Invariant Feature Transform),尺度不变特征变换匹配算法,是由David G. Lowe在1999年(《Object Recognition from Local Scale-Invariant Features》)提出的高效区域检测算法,在2004年(《Distinctive Image Features from Scale-Invariant Keypoints》)得以完善。
SIFT特征对旋转、尺度缩放、亮度变化等保持不变性,是非常稳定的局部特征,现在应用很广泛。SIFT算法是将Blob检测,特征矢量生成,特征匹配搜索等步骤结合在一起优化。
1. DOG尺度空间构造
尺度空间理论
尺度越大图像越模糊。
用机器视觉系统分析未知场景时,计算机并不预先知道图像中物体的尺度。我们需要同时考虑图像在多尺度下的描述,获知感兴趣物体的最佳尺度。另外如果不同的尺度下都有同样的关键点,那么在不同的尺度的输入图像下就都可以检测出来关键点匹配,也就是尺度不变性。 图像的尺度空间表达就是图像在所有尺度下的描述。
高斯模糊
高斯核是唯一可以产生多尺度空间的核。一个图像的尺度空间L(x, y, σ),定义为原始图像I(x, y)与一个可变尺度的2维高斯函数G(x, y, σ)的卷积运算。
二维空间高斯函数:$G(x_i,y_i,\sigma)=\frac{1}{2\pi\sigma^2}exp\lgroup-\frac{(x-x_i)^2+(y-y_i)^2}{2\sigma^2}\rgroup$
尺度空间:L(x, y, σ) = G(x, y, σ) * I(x, y)
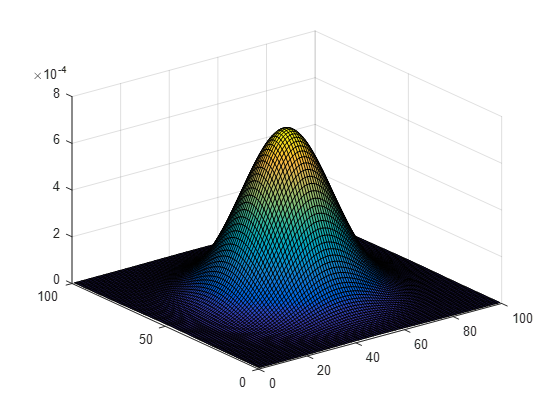
matlab代码:
1 | % 先限定三维图中的x,y轴坐标范围 |
分布不为零的点组成卷积阵与原始图像做变换,即每个像素值是周围相邻像素值的高斯平均。一个5*5的高斯模版如下所示:
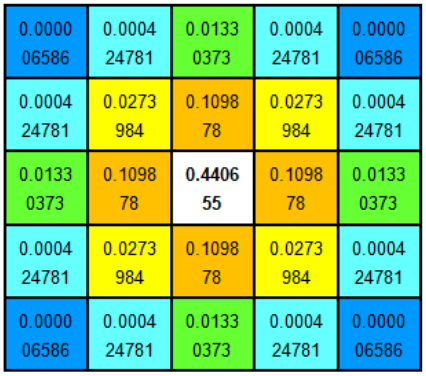
高斯模板是圆对称的。模板中心权重最大,距离中心越远权重越小。实际计算中,大于3σ以外的像素基本不起作用,计算可忽略。所以,单像素只需要计算(6σ + 1) ⋅ (6σ + 1)的方形区域。
高斯模糊是线性可分的。二维高斯矩阵变换可以通过在水平和竖直方向上用一维高斯矩阵变换相加得到。
当N为高斯核大小,m,n为图像长和宽时,直接计算复杂度为O(N2mn)次乘法;使用相加简化为O(Nmn + Nmn)。
openCV中的函数:
1 | void cv::GaussianBlur( |
- src - 输入图像
- dst - 与输入图像尺寸一致的输出图像
- ksize - 高斯核大小。可定制长宽,必须为正奇数,当为零是采用sigma计算
- sigmaX - X方向上的高斯核标准偏差
- sigmaY - Y方向上的高斯核标准偏差
- boerderType - 像素外推法
金字塔多分辨率
金字塔是早期图像多尺度的表示方式。图像金字塔化一般两个步骤:
- 使用低通滤波器(LPF)平滑图像;
- 对平滑图像降采样(通常$\frac{1}{2}$)
该方式能得到系列尺寸缩小的图片。
原图(l = 0)
$\frac{1}{2}(l=1)$
$\frac{1}{4}(l=2)$
$\frac{1}{8}(l=3)$
$\frac{1}{16}(l=4)$
matlab代码:
1 | lena=imread('lena.png'); |
可见对于二维图像,一个传统的金字塔,每一层图像尺寸为上一层的$\frac{1}{2}*\frac{1}{2}=\frac{1}{4}$。
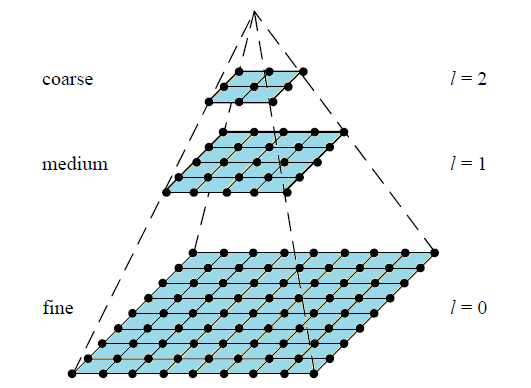
多尺度空间和金字塔多分辨率
尺度空间表达和金字塔分辨率表达的明显区别有:
- 尺度空间表达是由不同高斯核平滑卷积得到的,在所有尺度上分辨率相同;
- 金字塔多分辨率表达每层分辨率减少固定比率。
因此,金字塔多分辨率生成快,空间少,但局部特征描述单一;多尺度空间的图片局部特征可以在不同尺度描述,但随尺度参数增加会增加冗余信息。
高斯拉普拉斯金字塔( LoG)
LoG(Laplace of Gaussian),也称作拉普拉斯金字塔。其结合了尺度空间表达核金字塔多分辨率表达,在使用尺度空间时使用金字塔表示,其算子是对高斯函数进行拉普拉斯变换。 $$ L(x,y,\sigma)=\frac{\partial^2G}{\partial x^2} + \frac{\partial^2G}{\partial y^2} $$ 标准高斯卷积表达式G如下: $$ G(x,y,\sigma)=\frac{1}{2\pi\sigma^2}e^{-\frac{x^2+y^2}{2\sigma^2}} $$ 原图像与高斯卷积的结果求二阶偏导(拉普拉斯变换)如下: Δ[G(x, y, σ) * I(x, y)] = [ΔG(x, y, σ)] * I(x, y) = L(x, y, σ) * I(x, y) 对L求解如下: $$ \begin{align} \frac{\partial G}{\partial x} &= \frac{1}{2\pi\sigma^2}e^{-\frac{x^2+y^2}{2\sigma^2}}\cdot(-\frac{x}{\sigma^2})=-\frac{x}{2\pi\sigma^4}e^{-\frac{x^2+y^2}{2\sigma^2}} \\ \frac{\partial^2 G}{\partial x^2} &= \frac{\partial}{\partial x}\lgroup\frac{\partial G}{\partial x}\rgroup = -\frac{1}{2\pi\sigma^4}e^{-\frac{x^2+y^2}{2\sigma^2}}+\frac{x^2}{2\pi\sigma^6}e^{-\frac{x^2+y^2}{2\sigma^2}} \end{align} $$ 同理: $$ \frac{\partial^2 G}{\partial y^2} = -\frac{1}{2\pi\sigma^4}e^{-\frac{x^2+y^2}{2\sigma^2}}+\frac{y^2}{2\pi\sigma^6}e^{-\frac{x^2+y^2}{2\sigma^2}} $$
$$ \therefore L(x,y,\sigma)=\frac{\partial^2 G}{\partial x^2}+\frac{\partial^2 G}{\partial y^2} = -\frac{1}{\pi\sigma^4}[1-\frac{x^2+y^2}{2\sigma^2}]e^{-\frac{x^2+y^2}{2\sigma^2}} $$
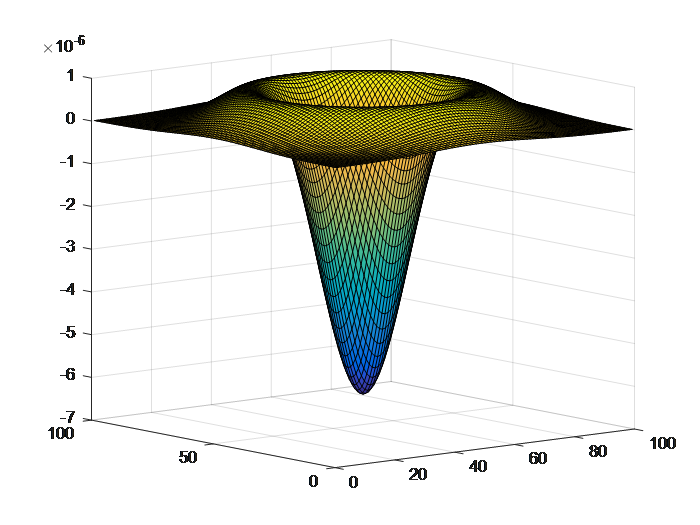
matlab代码:
1 | % 先限定三维图中的x,y轴坐标范围 |
LoG用来从金字塔低层图像重建上层未采样图像,在数字图像处理中也即是预测残差,可以对图像进行最大程度的还原,配合高斯金字塔一起使用。
高斯金字塔用来向下降采样图像,而拉普拉斯金字塔则用来从金字塔底层图像中向上采样重建一个图像。
在高斯金字塔中,要从金字塔第i层生成第i + 1层(我们表示第i + 1层为Gi + 1),我们先要用高斯核对Gi进行卷积,然后删除所有偶数行和偶数列。新得到图像面积会变为源图像的四分之一。按上述过程对输入图像G0执行操作就可产生出整个金字塔。
下式是LoG第i层的数学定义: $$ \begin{align} L_i &= G_i-Up(G_{i+1})\otimes g \\ &=G_i - PyrUp(G_{i+1}) \\ \end{align} $$ 式中,Gi表示高金字塔中第i层图像。Up()上采样操作是将Gi + 1层图像位置中为(x, y)的像素映射到图像(2x + 1, 2y + 1)的位置,其余位置用0填充。采样结果与高斯核g卷积,注意缩小的时候用什么核,这里就用什么核。Gi − Up(Gi + 1) ⊗ g可以描述为PyrUp(Gi + 1)函数。
也就是说,拉普拉斯金字塔是通过高斯金字塔图像减去先缩小后再放大的图像的一系列图像构成的。
高斯差分金字塔( DoG)
LoG的主要缺点是需要求二阶导,计算较复杂,因此我们就想用别的算子去近似它。DoG(Difference of Gaussian),相当于对LoG(σ2Δ2G)的近似计算,SIFT算法中,建议某一尺度的特征检测,可以通过两个相邻高斯尺度空间的图像相减,得到DoG的响应值图像D(x, y, σ)。然后仿照LoG方法,对D(x, y, σ)进行局部最大值搜索,在空间位置和尺度空间定位局部特征点。
DoG与LoG也存在以下关系: $$ \begin{align} D(x,y,\sigma) &= (G(x,y,k\sigma)-G(x,y,\sigma))*I(x,y) \\ &=L(x,y,k\sigma)-L(x,y,\sigma) \\ \end{align} $$ k为相邻两个尺度空间倍数的常数。
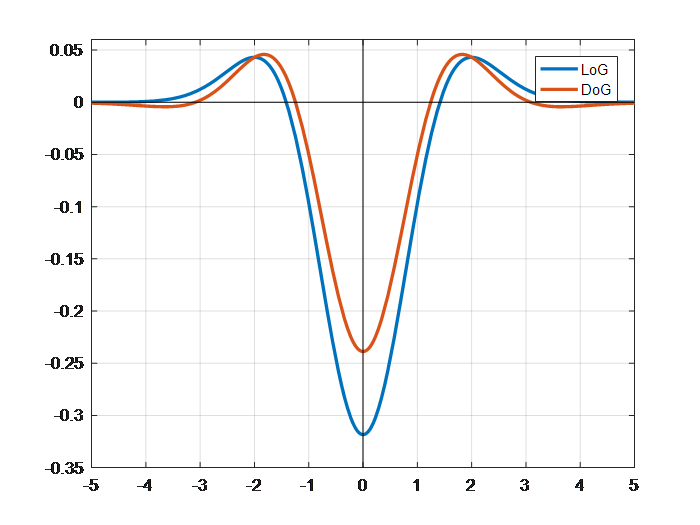
matlab绘图代码:
1 | %LoG与DoG一维函数图像差异 |
上图是某层DoG与LoG的对比。
构建高斯金字塔
为了得到DoG图像,先要构造高斯金字塔。 高斯金字塔在多分辨率金字塔简单降采样基础上加了高斯滤波,也就是对金字塔每层图像用不同参数的σ(上层为下层的k倍),做高斯模糊,使得每层金字塔有多张高斯模糊图像。
金字塔每层多张图像合称为一组(Octave),每组有多张(Interval)图像。另外,降采样时,金字塔上边一组图像的第一张图像(最底层的一张)是由前一组(下面一组)图像的倒数第三张(从上往下第三张)隔点采样得到。
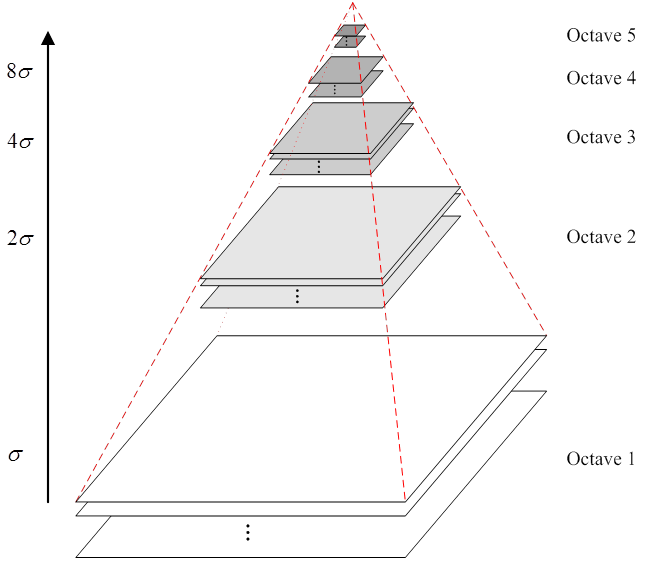
因此有以下特点:
在同一组内,不同层图像的尺寸是一样的,后一层图像的高斯平滑因子σ是前一层图像平滑因子的k倍;
在不同组内,后一组第一个图像是前一组倒数第三个图像的$\frac{1}{2}$采样,图像尺寸是前一组的$\frac{1}{4}$。
以下是openCV 2.4.2中高斯金字塔的构建源码:
1 | // 构建nOctaves组(每组nOctaveLayers+3层)高斯金字塔, nOctaves为输入变量 |
说明:
高斯金字塔的组数O = [log2(min(m, n))] − 3;
关于计算计算高斯模糊的系数σ,有以下关系:
$$ \sigma(o,s) = \sigma(o,0)\cdot2^{\frac{s}{S}} $$
且存在以下关系:
σ(o + 1, 0) = σ(o, S)
其中,σ为尺度空间坐标,o为组坐标,s为每组中的层座标,σ(o, 0)为该组的初始尺度,S为每组层数(3~5)。可以得到:
组内相邻图像尺度关系:$\sigma(o,s+1)=\sigma(o,s)\cdot2^\frac{1}{S}$
相邻组间尺度关系: $$ \begin{align} \sigma(o+1,s) &= \sigma(o+1,0)\cdot2^{\frac{s}{S}} \\ &= \sigma(o,S)\cdot2^{\frac{s}{S}} \\ &= \sigma(o,0)\cdot2^{\frac{s+S}{S}} \\ &=2\sigma(o,s) \end{align} $$
所以相邻两组的同一层尺度大小为2倍关系。
最终尺度序列可得: $$ \bar\sigma = 2^{o-1}(\sigma,k\sigma,k^2\sigma,\dots k^{s-1}\sigma),\ k=2^{\frac{1}{S}} $$ 即: $$ \sigma(o,s)=2^{o-1}k^{(s-1)}\sigma,\ k=2^{\frac{1}{S}} $$
$$ \begin{align} \bar\sigma_i&=\sqrt{k^{(i-1)}\sigma*k*k^{(i-1)}\sigma*k-k^{(i-1)}\sigma*k^{(i-1)}\sigma} \\ (\bar\sigma_i)^2&=k^{2(i-1)}\sigma^2(k^2-1) \\ &= k^{2(i-1)}\sigma^2(2^{\frac{2}{S}}-1) \end{align} $$
当且仅当S = 2时成立,此时每组2 + 3 = 5层
构建DoG金字塔
构建高斯金字塔之后,就是用金字塔相邻图像相减构造DoG金字塔。
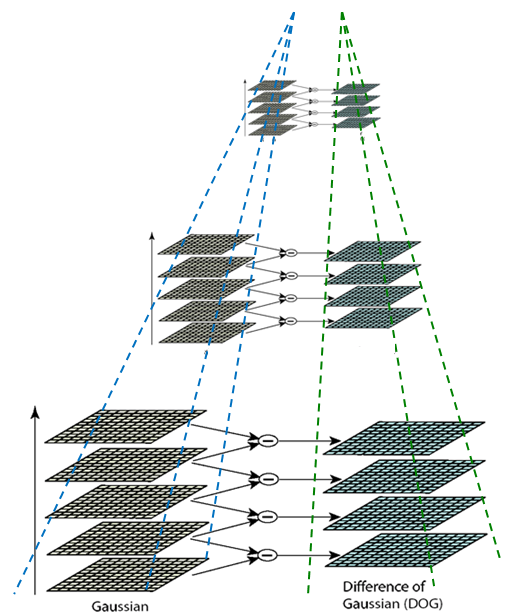
如上图所示,高斯尺度金字塔每组中有五层不同尺度图像,相邻两层相减得到四层DoG结果,接下来需要这四层DoG图像上寻找局部极值点(关键点)。
1 | //构建nOctaves组(每组nOctaveLayers+2层,因为相减生成会少一层)高斯差分金字塔 |
值得注意的是高斯金字塔每组为nOctaves+3层,为得到DoG金字塔相减计算后,会少一层为nOctaves+2层。
2. 关键点搜索与定位
DoG局部极值点
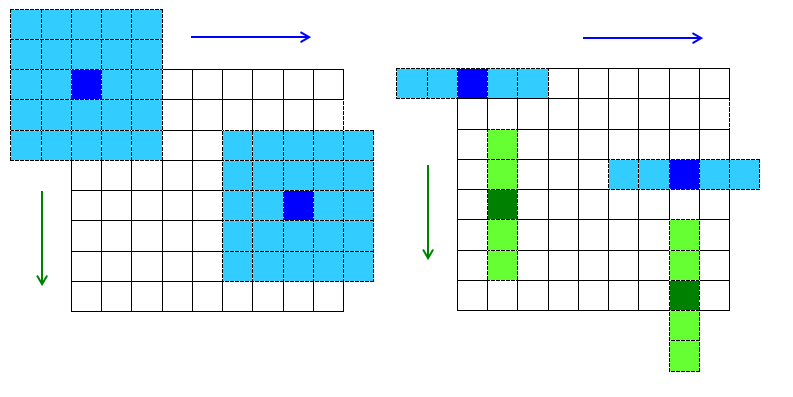
极值点定义:每一个像素点与它所有相邻点比较,当其大于(或小于)它的图像域和尺度域的所有相邻点时,即为极值点。
如下图所示,比较范围是一个3 × 3 × 3的立方体,中间检测点需与周围26个点比较,确保尺度空间和图像空间都为极值点。
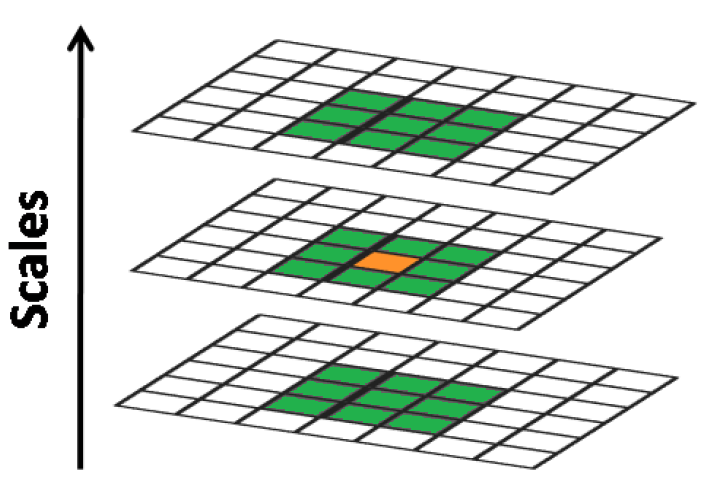
具体方法是:在每一组(Octaves)中,从第二层(设为当前层)开始搜索,此时第一层和第三层分别为二层的下层和上层;搜索完成后,置当前层为第三层,开始下次搜索;因此每层会被比较两次。通常我们将组编号索引从-1开始,每组除0层和最高层都会被当作当前搜索层。
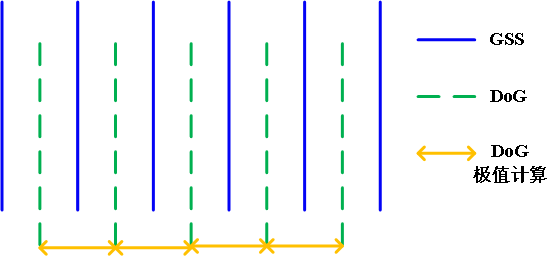
如上图,表示了高斯金字塔,DoG金字塔和DoG极值点计算层的关系。
关键点精确定位(DoG特征点的修正)
上述的的关键点计算中,使用的是离散空间的像素值点,但由于离散点并不能准确描述“真正”的极值点,存在误差,需要对DoG金字塔图像进行进一步拟合。
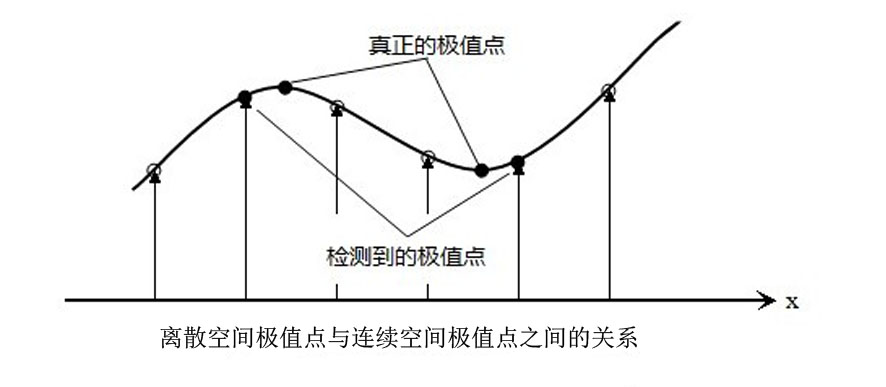
利用已知的离散空间点插值得到连续空间极值点的方法叫做子像元插值。
首先来看一个一维函数插值的例子f(x) = −3x2 + 2x + 6,如下图:
.png)
matlab绘图代码:
1 | syms f(x); |
图中可见,连续空间和离散空间的极值点并不重合。我们需要先引进Taylor(泰勒)展开式: $$ f(x)=\sum_{i=0}^{n} \frac{f^{(i)}(x_0)}{i!}(x-x_0)^i $$ 我们对函数f(x)使用泰勒级数展开: $$ \begin{align} f(x)& \approx f(0) + f'(0)x + \frac{f''(0)}{2}x^2 \\ f(x)& \approx 6 + 2x -3x^2 \end{align} $$ 补充——离散空间的一阶导数和二阶导数的求法: $$ \begin{align} f'(x)&=\frac{f(x+h)-f(x-h)}{2h} \\ f''(x)&=\frac{f(x+h)+f(x-h)-2f(x)}{h^2} \end{align} $$ 使用泰勒展开后求得f(x)后,可以求得连续函数f(x)真正的极大值坐标: $$ \begin{align} f'(x)=2-6x=0 \Rightarrow \bar x= \frac{1}{3} \\ f(\bar x)=6+2\times\frac{1}{3}-3\times(\frac{1}{3})^2=6\frac{1}{3} \end{align} $$ 对于二维函数,其泰勒展开为: $$ f(x,y)\approx f(0,0)+(\frac{\partial f}{\partial x}x+\frac{\partial f}{\partial y}y)+\frac{1}{2}(x^2\frac{\partial^2f}{\partial x \partial y}+2xy\frac{\partial^2f}{\partial x \partial y}+y^2\frac{\partial^2f}{\partial y \partial y}) $$ 若将$\begin{bmatrix} x\\ y\end{bmatrix}$表示成向量x⃗,上式变形为: $$ f(\vec{x})\approx f(\vec{0})+\frac{\partial f^T}{\partial x}x+ \frac{1}{2}x^T\frac{\partial^2f}{\partial x^2}x $$ 注意:此处的存在的一阶导数和二阶导数都是$x= \begin{bmatrix} 0\\ 0\end{bmatrix}$这个点时的一阶导和二阶导的值。
对上式求导,以便取得极值点: $$ \frac{\partial f}{\partial x} = \frac{\partial f^T}{\partial x}+\frac{1}{2}(\frac{\partial^2f}{\partial x^2}+\frac{\partial^2f^T}{\partial x^2})x=0 $$ 此处两个导数和之前一样,此时可以求得真正的极值点: $$ \hat x=-\frac{\partial^2f^{-1}}{\partial x^2}\cdot\frac{\partial f}{\partial x} $$ 带入泰勒展开式,得到极值点函数值: $$ f(\hat x)=f(\vec{0})+\frac{\partial f^T}{\partial x}\hat{x}+\frac{1}{2}\hat{x}^T\frac{\partial^2f}{\partial x^2}\hat{x}=f(\vec{0})+\frac{1}{2}\frac{\partial f^T}{\partial x}\hat{x} $$ 我们回到DoG函数,同样得到D(X)的泰勒展开: $$ D(X)\approx D+\frac{\partial D^T}{\partial X}X+ \frac{1}{2}X^T\frac{\partial^2D}{\partial X^2}X $$ 此处的D即是在0点的函数值。设极值点为X̂ = (x, y, σ)T
若X̂在任何方向上的偏移大于$\frac{1}{2}$时(一格的一半),意味着插值中心点已经偏移到它的临近点上,所以这样的点需要删除。另外,下示程序还删除了极值小于0.04的点(|D(X̂)| < 0.04,图像的灰度值在0~1之间),其响应值过小,这样的点易受噪声的干扰而变得不稳定,所以也要被删除。
1 | // 在DoG尺度空间寻特征点(极值点) Bad features are discarded |
角检测器
在接下推导时,我们需要先了解角检测器原理。
现有对角点的定义有两个版本:
- 角点可以是两个边缘的角点;
- 角点是邻域内具有两个主方向的特征点;
角点检测算法大致可以分为三类:
- 基于模板(基于二值图像)
- 基于边缘特征(基于轮廓曲线,例如CSS方法)
- 基于亮度变化(基于灰度图像,主要有Moravec算子、Forstner算子、Harris算子、SUSAN算子等)
下面会说明Harris角点检测的算法原理,openCV的函数接口是cornerHairrs();另外比较著名的角点检测方法还有Shi-Tomasi算法,这个算法开始主要是为了解决跟踪问题,用来衡量两幅图像的相似度,我们也可以把它看为Harris算法的改进。OpenCV中已经对它进行了实现,接口函数名为GoodFeaturesToTrack()。
另外还有一个著名的角点检测算子即SUSAN(Smallest Univalue Segment Assimilating Nucleus,最小核值相似区)算子。SUSAN使用一个圆形模板和一个圆的中心点,通过圆中心点像素与模板圆内其他像素值的比较,统计出与圆中心像素近似的像元数量,当这样的像元数量小于某一个阈值时,就被认为是要检测的角点。可以把SUSAN算子看为Harris算法的一个简化。这个算法原理非常简单,算法效率也高,所以在OpenCV中,它的接口函数名称为:FAST() 。
先引入曲率的概念:曲线的曲率(curvature)就是针对曲线上某个点的切线方向角对弧长的转动率,通过微分来定义,表明曲线偏移直线的程度。数学上表明曲线在某一点的弯曲程度的数值。曲率越大,表示曲线的弯曲程度越大。曲率的倒数就是曲率半径。
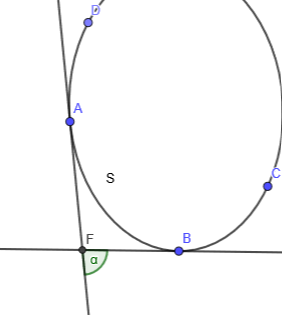
例如在曲线CD上点A和临近一点B各做一条切线,A和B之间的弧长为S̃,两条切线夹角为α,则曲线CD在A点的曲率为:$\lim\limits_{\Delta S\to 0}\frac{\alpha}{\Delta S}$
Harris角点
人眼对角点的识别通常是在一个局部的小区域或小窗口完成的。
- 如果在各个方向上移动这个特征的小窗口,窗口内区域的灰度发生了较大的变化,那么就认为在窗口内遇到了角点。
- 如果这个特定的窗口在图像各个方向上移动时,窗口内图像的灰度没有发生变化,那么窗口内就不存在角点;
- 如果窗口在某一个方向移动时,窗口内图像的灰度发生了较大的变化,而在另一些方向上没有发生变化,那么,窗口内的图像可能就是一条直线的线段。
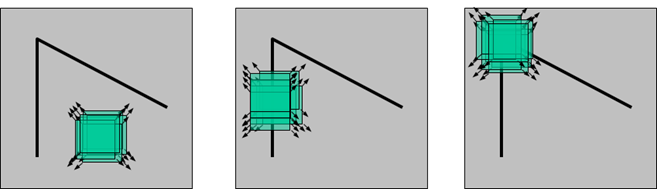
对于图像I(x, y),当在点(x, y)处平移(Δx, Δy)后的自相似性,可以通过自相关函数给出: $$ c(x,y;\Delta x,\Delta y)=\sum\limits_{(u,v)\in W(x,y)}w(u,v)(I(u,v)–I(u+\Delta x,v+\Delta y))^2 $$ 其中,W(x, y)是以点(x, y)为中心的窗口,w(u, v)为加权函数,它既可是常数(下图左),也可以是高斯加权函数(下图右)。

对图像I(x, y)在平移(Δx, Δy)后进行一阶泰勒近似: $$ \begin{align} I(u+\Delta x,v+\Delta y) &= I(u,v)+I_x(u,v)\Delta x+I_y(u,v)\Delta y+O(\Delta x^2,\Delta y^2) \\ &\approx I(u,v)+I_x(u,v)\Delta x+I_y(u,v)\Delta y \\ \end{align} $$ 其中,Ix、Iy是图像I(x, y)的偏导数,这样的话,自相关函数则可以简化为(暂时省略w(u, v),不影响结算结果): $$ \begin{align} c(x,y;\Delta x, \Delta y) & \approx \sum_\limits{w}(I_x(x,y)\Delta x + I_y(x,y)\Delta y)^2 \\ &= \begin{bmatrix} \Delta x & \Delta y\end{bmatrix}M(x,y) \begin{bmatrix} \Delta x\\ \Delta y\end{bmatrix} \end{align} $$ 其中 $$ \begin{align} M(x,y) &= \sum_\limits{w} \begin{bmatrix} I_x(x,y)^2 & I_x(x,y)I_y(x,y) \\ I_x(x,y)I_y(x,y) & I_y(x,y)^2\end{bmatrix} \\ &=\begin{bmatrix} \sum_w I_x(x,y)^2 & \sum_w I_x(x,y)I_y(x,y) \\ \sum_w I_x(x,y)I_y(x,y) & \sum_w I_y(x,y)^2\end{bmatrix} \\ &=\begin{bmatrix} A & B \\ B & C\end{bmatrix} \end{align} $$ 也就是说图像I(x, y)在点(x, y)处平移(Δx, Δy)后的自相关函数可以近似为二项函数: c(x, y; Δx, Δy) ≈ AΔx2 + 2BΔxΔy + CΔy2 其中 $$ A=\sum_\limits{w}I_x^2,\quad B=\sum_\limits{w}I_xI_y,\quad C=\sum_\limits{w}I_y^2 $$ 二次项函数本质上就是一个椭圆函数。如下图所示,椭圆一般方程为: Ax2 + Bxy + Cy2 + Dx + Ey + 1 = 0 可把$[\Delta x, \Delta y]M(x,y) \begin{bmatrix} \Delta x\\ \Delta y\end{bmatrix}=A\Delta x^2 + 2B\Delta x \Delta y+C\Delta y^2=1$类比于一般椭圆。椭圆的扁率和尺寸是由M(x, y)的特征值λ1、λ2决定的,椭圆的方向是由M(x, y)的特征矢量决定的。
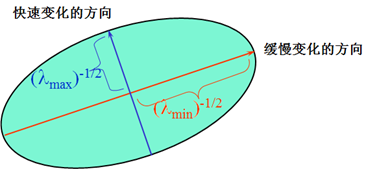
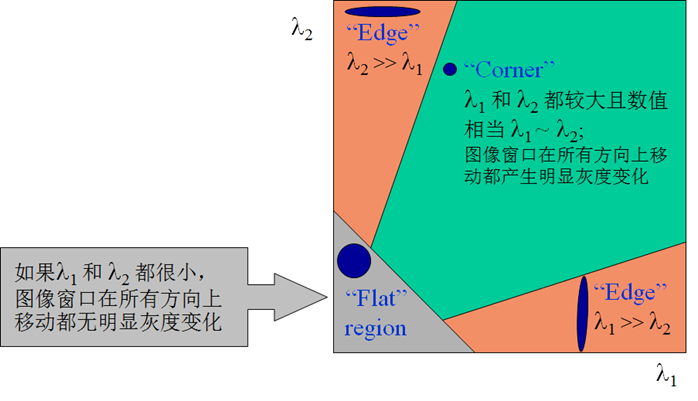
椭圆函数特征值与图像中的角点、直线(边缘)和平面之间的关系如下图所示。共可分为三种情况:
- 图像中的直线。 一个特征值大,另一个特征值小,λ1 ≪ λ2或λ1 ≫ λ2。自相关函数值在某一方向上大,在其他方向上小。
- 图像中的平面。 两个特征值都小,且近似相等;自相关函数数值在各个方向上都小。
- 图像中的角点。 两个特征值都大,且近似相等,自相关函数在所有方向都增大。
根据二次项函数特征值的计算公式,我们可以求M(x, y)矩阵的特征值。但是Harris给出的角点差别方法并不需要计算具体的特征值,而是计算一个角点响应值R来判断角点。R的计算公式为: R = detM − α(traceM)2 示中,detM为矩阵$M=\begin{bmatrix} A & B \\ B & C\end{bmatrix}$的行列式;traceM为矩阵M的迹;α经常为常数,取值范围为0.04 ∼ 0.06。实际上,特征值是隐含在detM和traceM中的,因为: $$ \begin{align} detM&=\lambda_1\lambda_2=AC-B^2 \\ traceM&= \lambda_1+\lambda_2 = A+C \end{align} $$
Harris角点算法实现
根据上述讨论,可以将Harris图像角点检测算法归纳如下,共分以下五步:
计算图像 I(x, y)在X和Y两个方向的梯度Ix、Iy。 $$ I_x=\frac{\partial I}{\partial x}=I\otimes\begin{pmatrix} -1& 0 &1\end{pmatrix}, I_y=\frac{\partial I}{\partial y}=I\otimes\begin{pmatrix} -1& 0 &1\end{pmatrix}^T $$ 卷积$\begin{pmatrix} -1& 0 &1\end{pmatrix}$的结果该位置的后一个像素与前一个像素之差。
计算图像两个方向梯度的乘积。
Ix2 = Ix ⋅ Iy, Iy2 = Iy ⋅ Iy, Ixy = Ix ⋅ Iy
- 使用高斯函数对Ix2、Iy2和Ixy进行高斯加权(取σ = 1),生成矩阵M的元素A、B和C。
$$ \begin{align} A&=g(I_x^2) =I_x^2\otimes w \\ B&=g(I_{xy})=I_{xy} \otimes w\\ C&=g(I_y^2)=I_y^2\otimes w \\ \end{align} $$
- 计算每个像素的Harris响应值R,并对小于某一阈值t的R置为零。
R = (detM − α(traceM)2 < t) ? 0 : detM − α(traceM)2
- 在3 × 3或5 × 5的邻域内进行非极大值抑制(可以理解为局部最大搜索),局部最大值点即为图像中的角点。
参数α的影响
假设已经得到了矩阵M的特征值λ1 ≥ λ2 ≥ 0,令λ2 = kλ1, 0 ≤ k ≤ 1。由特征值与矩阵M的迹和行列式的关系可得: $$
detM=\prod_\limits{i}\lambda_i,\quad traceM=\sum_\limits{i}\lambda_i
$$ 可以得到角点的响应R:
R = λ1λ2 − α(λ1 + λ2)2 = λ12[k − α(1 + k)2]
假设R ≥ 0,可得: $$
0\leq\alpha\leq\frac{k}{(1+k)^2}\leq0.25
$$
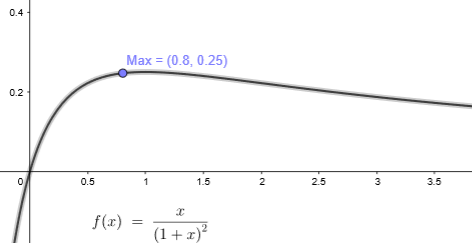
对于较小的k值,R ≈ λ2(k − α), α < k。
由此,可以得出这样的结论:增大α的值,将减小角点响应值R,降低角点检测的灵性,减少被检测角点的数量;减小α值,将增大角点响应值R,增加角点检测的灵敏性,增加被检测角点的数量。
Harris的特性
- Harris角点检测算子对亮度和对比度的变化不敏感;
- Harris角点检测算子具有旋转不变性;
- Harris角点检测算子不具有尺度不变性。
openCV Hairrs角点检测函数
OpenCV的Hairrs角点检测的函数为cornerHairrs(),但是它的输出是一幅浮点值图像,浮点值越高,表明越可能是特征角点,我们需要对图像进行阈值化。
1 | void cornerHarris(InputArray src, OutputArray dst, int blockSize, int apertureSize, double k, int borderType = BORDER_DEFAULT); |
- src – 输入的单通道8-bit或浮点图像。
- dst – 存储着Harris角点响应的图像矩阵,大小与输入图像大小相同,是一个浮点型矩阵。
- blockSize – 邻域大小。
- apertureSize – 扩展的微分算子大。
- k – 响应公式中的参数α 。
- boderType – 边界处理的类型。
删除边缘效应
为了得到稳定的特征点,除了之前删除DoG响应较低的点,我们还应该注意DoG对图像边缘有较强的响应值,有些极值点的位置是在图像的边缘位置的,因为图像的边缘点很难定位,同时也容易受到噪声的干扰,我们把这些点看做是不稳定的极值点,需要进行去除。
此处先引进Hessian矩阵,Hessian矩阵是一个多元函数的二阶偏导数构成的方阵,描述了函数的局部曲率。在边缘梯度的方向上主曲率值比较大,而沿着边缘方向则主曲率值较小。候选特征点的DoG函数的主曲率与2 × 2Hessian矩阵H的特征值成正比: $$ H(x,y)=\begin{bmatrix} I_{xx}(x,y) & I_{xy}(x,y) \\ I_{yx}(x,y) & I_{yy}(x,y)\end{bmatrix} $$ 注意:Harris角检测利用的是一阶导数的协方差矩阵,Hessian是二阶偏导数,他们的形式和对角点的判据差不多,所以容易混淆。
另外,根据Hessian矩阵对称性,如果函数I的二阶偏导数连续,则二阶偏导数的求导顺序没有区别,即Ixy(x, y) = Iyx(x, y)。
Ixx(x, y),Ixy(x, y) 和Iyy(x, y)是候选点邻域位置差分求得的,可参考Harris求法。
为了避免求具体的值,可以使用H特征值的比例表示H。设α = λmax为H的最大特征值,β = λmin为H的最小特征值。则有: $$ \begin{align} traceH &= I_{xx}(x,y)+I_{yy}(x,y)=\alpha + \beta \\ detH &= I_{xx}(x,y)I_{yy}(x,y)-I_{xy}^2(x,y)=\alpha \cdot \beta \end{align} $$ 同样:traceH表示矩阵H的迹,detH表示H的行列式。
令$\gamma=\frac{\alpha}{\beta}$表示最大特征值与最小特征值的比值,则: $$ \frac{traceH^2}{detH}=\frac{(\alpha + \beta)^2}{\alpha \beta} =\frac{(\gamma+1)^2}{\gamma} $$ 上式的结果与两个特征值的比例有关,和具体的大小无关。当两个特征值相等时其值最小,并且随着γ 的增大而增大。因此为了检测主曲率是否在某个阈值Tγ下,只需检测: $$ \frac{traceH^2}{detH} > \frac{(T_\gamma+1)^2}{T_\gamma} $$ 如果上式成立,则剔除该特征点,否则保留。(Lowe论文中取Tγ = 10)
1 | // Interpolates a scale-space extremum's location and scale to subpixel |
3. 方向赋值
上面我们已经找到了关键点。为了实现图像旋转不变性,需要根据检测到的关键点局部图像结构为特征点方向赋值。我们使用图像的梯度直方图法求关键点局部结构的稳定方向。
梯度方向和幅值
在前文中,精确定位关键点后也找到特征点的尺度值σ ,根据这一尺度值,得到最接近这一尺度值的高斯图像: L(x, y) = G(x, y, σ) ⊗ I(x, y) 使用有限差分,计算以关键点为中心,以3 × 1.5σ为半径的区域内图像梯度的幅值m(x, y)和幅角θ(x, y),公式如下: $$ \begin{align} m(x,y) &= \sqrt{(L(x+1, y) - L(x-1,y))^2+(L(x,y+1)-L(x,y-1))^2} \\ \theta(x,y)&=arctan(\frac{L(x,y+1)-L(x,y-1)}{L(x+1,y)-L(x-1,y)}) \end{align} $$
梯度直方图
在完成关键点邻域内高斯图像梯度计算后,使用直方图统计邻域内像素对应的梯度方向和幅值。
梯度方向直方图的横轴是梯度方向角,纵轴是剃度方向角对应的梯度幅值累加值。梯度方向直方图将0°~360°的范围分为36个柱,每10°为一个柱。可看作一定区域内的图像像素点对关键点方向生成所作的贡献。
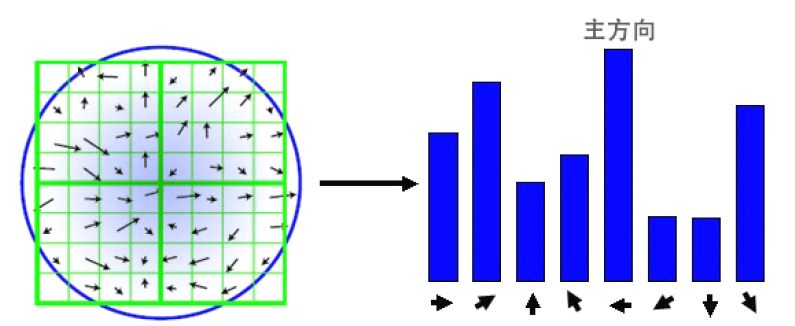
在计算直方图时,每个加入直方图的采样点都使用圆形高斯函数函数进行了加权处理,也就是进行高斯平滑。Lowe建议子区域的像素的梯度大小σ = 0.5d的高斯加权计算。这主要是因为SIFT算法只考虑了尺度和旋转不变形,没有考虑仿射不变性。通过高斯平滑,可以使关键点附近的梯度幅值有较大权重,从而部分弥补没考虑仿射不变形产生的特征点不稳定。
通常离散的梯度直方图要进行插值拟合处理,以求取更精确的方向角度值。
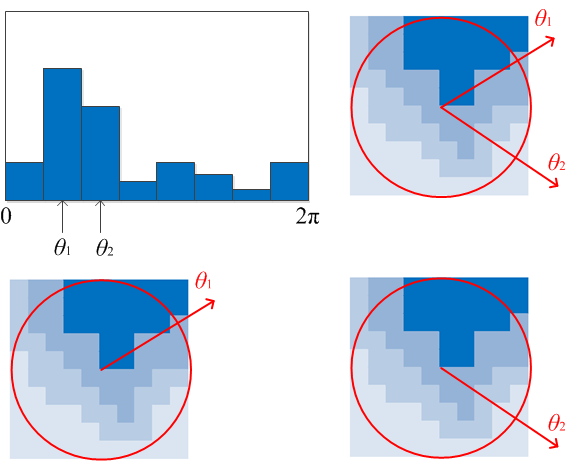
关键点方向
直方图峰值代表该关键点处邻域内图像梯度的主方向,也就是该关键点的主方向。在梯度方向直方图中,当存在另一个相当于主峰值80%能量的峰值时,则将这个方向认为是该关键点的辅方向。
所以一个关键点可能检测得到多个方向,这可以增强匹配的鲁棒性。Lowe的论文指出大概有15%关键点具有多方向,但这些点对匹配的稳定性至为关键。
获得图像关键点主方向后,每个关键点有三个信息(x, y, σ, θ):位置、尺度、方向。
由此我们可以确定一个SIFT特征区域。通常使用一个带箭头的圆或直接使用箭头表示SIFT区域的三个值:中心表示特征点位置,半径表示关键点尺度(r = 2.5σ),箭头表示主方向。
具有多个方向的关键点可以复制成多份,然后将方向值分别赋给复制后的关键点。如下图:
3. 关键点描述
上文找到的关键点(SIFT特征点)包含位置、尺度和方向的信息。接下来的步骤是关键点描述,即用用一组向量将这个关键点描述出来,这个描述子不但包括关键点,也包括关键点周围对其有贡献的像素点。
用来作为目标匹配的依据(所以描述子应该有较高的独特性,以保证匹配率),也可使关键点具有更多的不变特性,如光照变化、3D视点变化等。
SIFT描述子h(x, y, θ)是对关键点附近邻域内高斯图像梯度统计的结果,是一个三维矩阵,但通常用一个矢量来表示。特征向量通过对三维矩阵按一定规律排列得到。
描述子采样区域
特征描述子与关键点所在尺度有关,因此对梯度的求取应在特征点对应的高斯图像上进行。
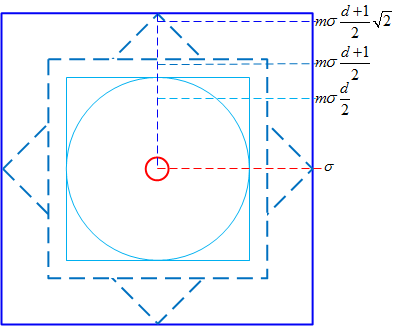
将关键点附近划分成d × d个子区域,每个子区域尺寸为mσ个像元(d = 4,m = 3,σ为尺特征点的尺度值)。考虑到实际计算时需要双线性插值,故计算的图像区域为mσ(d + 1),再考虑旋转,则实际计算的图像区域为$\sqrt{2}m\sigma(d+1)$,如下图所示:
区域坐标轴旋转
为了保证特征矢量具有旋转不变性,要以特征点为中心,在附近邻域内旋转θ角,即旋转为特征点的方向。
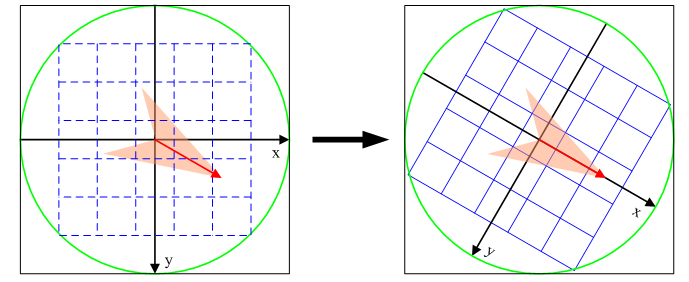
旋转后区域内采样点新的坐标为: $$ \begin{pmatrix} x' \\ y'\end{pmatrix} = \begin{pmatrix} cos\theta & -sin\theta \\ sin\theta & cos\theta\end{pmatrix} \begin{pmatrix} x \\ y\end{pmatrix} $$
计算采样区域梯度直方图
将旋转后区域划分为d × d个子区域(每个区域间隔为mσ 像元),在子区域内计算8个方向的梯度直方图,绘制每个方向梯度方向的累加值,形成一个种子点。 与求主方向不同的是,此时,每个子区域梯度方向直方图将0°~360°划分为8个方向区间,每个区间为45°。即每个种子点有8个方向区间的梯度强度信息。由于存在d × d,即4 × 4个子区域,所以最终共有4 × 4 × 8 = 128个数据(Lowe建议的数据),形成128维SIFT特征矢量。
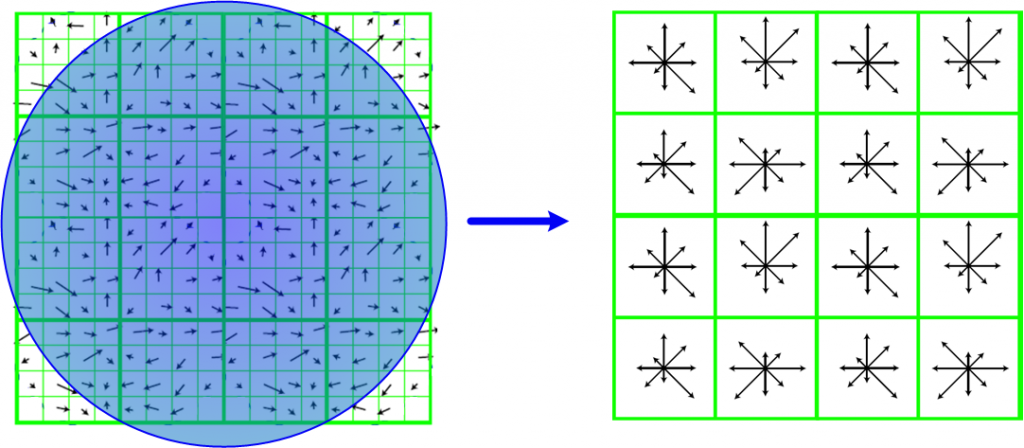
对特征矢量需要加权处理,加权采用$\frac{m\sigma d}{2}$的标准高斯函数。为了除去光照变化影响,还有进一步归一化处理。
至此SIFT描述子生成,SIFT算法也基本完成了。